Palmer LTER Data Management
As a Long-term Ecosystem Research (LTER) site, PAL is dedicated to collecting and maintaining long-term datasets crucial for the study of the environment and ecosystem of the Palmer Station area and West Antarctic Peninsula (WAP). All LTER sites are expected to make their data available within two years of collection.
This guide provides a high-level overview of the data management process adopted by Palmer LTER and who is responsible for each step.
Data Management Workflow
The PAL data management process supports the full data lifecycle, from collection through archiving. It currently consists of the following steps:
- New observations or samples are collected by the research teams during the annual field season and cruise, following documented procedures.
- Raw data files and processed sample information are stored and backed up locally by each research group. When necessary, these archives are passed onto new research team members.
- Required dataset updates (new versions) and additions (new datasets) are tracked in a central “to do list” database by the IM. As needed, the IM assigns new datasets a unique identifier. The status and progress of each dataset version is regularly communicated with the PAL team.
- Processed data is formatted, reviewed, cleaned, and merged into an existing time series (if applicable), typically in CSV format. This is typically handled by the research team.
- Data and metadata are updated and reviewed in ezEML by both the research team and IM.
- EML data packages are exported from ezEML (and manually edited if needed) and published to the EDI archive as a new data package or a revision of an existing one.
- Users can access the archived datasets directly from the EDI data portal, or via the searchable list on the PAL website. Dataset citations should point to the official archive on EDI, using the DOI they provide for each version.
- Selected datasets will also be published to our local ERDAPP server for direct access and visualization by researchers and educational audiences.
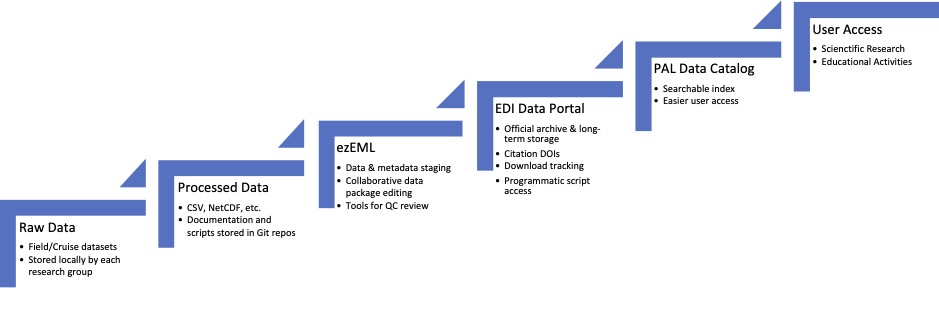
The Palmer LTER data processing workflow (as of 2024).
Data & Sample Collection
The PAL project collects long-term core datasets (e.g., phytoplankton, krill distributions, and penguin population studies), and shorter-term research project datasets during both field seasons at the Palmer Station and aboard annual LTER cruises. Sampling aboard the ship and on station has been standardized over the years, and each research group’s sampling and analysis standards/protocols have been tuned to follow PAL, LTER, and community accepted best practices. All shipboard sampling events are assigned an event number using the ship’s onboard event logging system and individual samples are assigned related numbers that can be used later to provide coordination between sample analyses and post-season or post-cruise processing. Similar event logging and indexing is done for station sampling.
Generally, each group designates one person to ensure their data collection adheres to existing standard operating procedures or field sampling protocols. Data validation is done by lab personnel unless PAL IM assistance is requested. For example, the phytoplankton group regularly updates an extensive manual that documents instrument setup, sample processing, and storage procedures for each of their regular measurements. The group’s research tech is responsible for maintaining the manual, training station and cruise personnel, and reviewing collected datasets following each season.
Each research group (PO, Sea Ice, Phyto, Microbes, Zoo, Sea Birds, Whales, Modelling) is responsible for storing and maintaining their own archive of raw digital data and physical samples (if needed), relying on their local university IT and physical storage facilities. In addition, Rutgers maintains a digital archive of all core ship and station raw data files in a robust, secure, and well backed-up file system.
Data Processing
Data for the PAL project is archived according to policies and requirements set forth by NSF and the LTER Network. Following the field season, the IM works with the research team to properly update, describe, and archive each dataset. Long-term datasets are incorporated into existing time series through a documented and structured workflow that enables process consistency and tracking. We are in the process of moving several datasets to a GitHub-based workflow that documents changes to the raw, processed, and merged datafiles, along with any code necessary to create combined datasets. In the past, each research team would process the most recent data and send it to the IM, who would then append it to the long-term timeseries. Our new workflow asks researchers to review the full timeseries prior to submission, rather than simply reviewing the most recent year.
Data and Metadata Formats
Archived core measurements from PAL annual cruises and station seasons are generally made available as CSV files, to support wide adoption and easy usage. When appropriate, larger, or more complex dataset formats are utilized following community practices. For example, a new historical timeseries of Glacier terminus lines was provided as an open-source GeoPackage file, and we are currently working on a new CTD dataset that will be based on the NCEI NetCDF Profile Templates. As we look to share more advanced datasets in the future (e.g. IFCB imagery, acoustic moorings, drone survey data), we anticipate creating more hybrid datasets consisting of CSV index files along with other data file formats.
Metadata for new and existing datasets is formatted as EML (Ecological Metadata Language), using EDI’s new ezEML tool. ezEML includes the LTER controlled vocabulary for keywords and the LTER unit directory for standardizing metadata values. Recent upgrades to the data processing workflow have sought to align PAL IM with the “Best Practices for Dataset Management in EML” (currently version 3), which includes adding metadata tags for geographic coverage, taxonomy, project and funding sources, ORCID/ROR identifiers, and dataset provenance. Recent updates have also focused on improving the abstracts, methods, and maintenance notes, which we now use to document the changes made in each version.
Data QC, Archiving, and Storage
PAL datasets are primarily archived on the Environmental Data Initiative (EDI) data portal, as required by the LTER program. Most PAL data packages are updated once per year, following the field season and any necessary post-processing and review. Datasets are typically staged in ezEML by the IM or (more recently thanks to one-on-one training) the responsible science lead. They are then uploaded into EDI after the IM and science lead have both reviewed the data and metadata for any issues. ezEML’s new metadata check, data QC check, and data explorer features have greatly aided this process, ensuring the data packages are complete and free from major errors.
Several datasets are archived outside of the EDI workflow.
- Standard shipboard measurements from PAL annual cruises (e.g., CTD, ADCP) are collected by the ship techs and made available by the Rolling Deck to Repository (R2R) project and archived with the Marine Geoscience Data System (MGDS).
- Standard station measurements (weather, waterwall, snow stakes), which fall under the responsibility of station staff, are available in the AMRDC data repository.
- Glider datasets are available on the Rutgers glider data portal and archived in the IOOS Glider DAC.
- One genomic dataset is currently archived with NDBI.
- Research model datasets and code that are created for specific papers are generally archived on Zenodo.
In compliance with NSF’s specific requirements for Antarctic sites, the PAL project and its data are also listed with the U.S. Antarctic Program Data Center (USAP-DC).
Data Availability
Annual cruise and station datasets are typically processed and made available in the EDI archive within 6-12 months following each field season. Physical samples (e.g. chlorophyll, biopsies, oxygen isotopes) generally require additional time for processing as they depend on shipping and processing lab availability, though our goal is to make them available within 24 months.
Data Usage Policy
In keeping with LTER recommendations, we generally release all datasets as Creative Commons Attribution (CC-BY), to facilitate collaboration with and usage by other researchers and educators. For more information, please see the PAL Data Policy.
More Information
For more guidance, please see:
